Movie Ranking Fun
I have officially added a page to share my top 50 movies based on my MovieRank tool. As the page explains, I built a tool which pulls in movie information and lets me bash them against each other to generate Elo rankings.
The project is inspired by a website, FlickChart.com. As I recently learned, they've updated their system, but the original structure was that when you had two movies face off, if the winner was the lower ranked movie it was placed above the movie that it beat. This ended up with some weird and undesirable movie rankings and it was very hard for movies to drop down in rankings. There are problems with an Elo based system (such as, it takes a lot of matches to generate a comprehensive ranking list) but overall I prefer this method.
As I noted, the system was recently updated, which the site owner actually shared with me on Bluesky:
 |
|
Nothing like some morning bug fixing to start your day. I was doing some tweaks yesterday and inadvertantly broke the nightly automated posting script.
|
 Yesterday's Claude Experiments
Yesterday's Claude Experiments
So I've been playing with Claude programming for a while via the web browser, this week I added it into my desktop VS Code to see how it worked. I pay for the minimum for a Claude account and I wasn't sure how it would work for me since I wasn't paying for Claude Code higher tiers.
Turns out, it works very well. Basically I get a certain amount of usage in hour chunks, and also overall for a week. After two days of use I've used roughly half of the week's quota. Which, honestly is pretty good for my casual project use case.
The quality of the code has been largely very solid. Everything I'm asking it to do are things which have well defined patterns which makes the quality better since it has more experience to pull from.
I also experimented with using self hosted Qwen 3.5 Coder and unfortunately the coding quality gap remains quite noticeable. Hopefully someday.
Claude enabled me to work through basically my entire backlog of Glowbug bugs and feature ideas. Many of these being things from over a year ago where the friction of doing it overcame my need to do it since this is a personal project.
Beyond those, I did some quality of life updates and general improvements.
Here is an incomplete list:
- Refactored the publish functionality for the statice website to make it smarter. Since I wrote it, it has basically required full archive updates on every publish.
- A general pass of security vulnerabilities and bugs identified in code
- Updated and improved the template engine in Glowbug
- Updated and improved how tags are handled by the system, including improving my admin page for them and adding tag archive pages with pagination for ones which go very long
- Added new code that allows me to input footnotes as part of a post.
- Fixed the bug with how the spoiler function works where it now hides text across multiple lines, this was a longstanding bug but since I use the spoiler tag so infrequently it's languished in the backlog
- Added an improved system for managing my movie radars for rating them, including integrating them directly into search and pulling movie information via API. Previously they were just implemented in a post's body with no overall tracking.
- I realized my coding backlog / todo is short enough that I should implement it into glowbug's admin itself rather than use a 3rd party tracker. So we coded a simple tracker into the admin section.
- I had it rewrite and improve most of my admin pages. They are all still barebones, but it added functionality and improved how they perform.
To be clear, in all cases, I review the code it writes. I don't merge anything without reading it and making sure I understand it or understand the gist of it.
It's been an interesting experiment and I definitely see the value for my use cases as a hobbyist coder and since I am using well trodden and documented languages and use cases. There are definitely still bugs it creates that I have to generate, but it has definitely saved me time overall these past few days.
|
This is an experimental post which utilizes new functions on the blog.1Alphabet soup anyone? This is a feature I've had on my backlog for a while and I'm finally implementing for potential future use in the blog.
We'll see how it does, I'm not sure.2Well, that's not true, I kind of know. I looked at the code, although I did use Claude to code this update for me as I experiment with it for desktop coding projects.
Also using this to explore if a fix for a long standing blog bug is fixed.
It was literally a bug in my tracker for 18 months...
|
As is tradition for this time of year, I've started picking up on side coding projects once again, including Glowbug - my custom CMS for this blog. I did some backend tweaking - fixing a few lingering bugs and adding some admin functionality which I needed.
I also did the (somewhat) yearly update of the About Me page. Adding a TLDR at the top, and then adding my short summation for 2025 to the end.
|
It must be winter because I just opened VSCode and made an update to my blog's backend code.
|
"Write 'Freehold' Software"
A blog entry where the author dives into the need to support software which is not a service, a term he proposes be 'freehold' to make use of the term's definition as it relates to real estate: "Permanent and absolute tenure of land or property with freedom to dispose of it at will."
|
Boneheaded mistake on the new search - the server code required a user to be logged into the backend. Oops.
That works for me, but not so much for you. (Whoever you may be.)
|
Site search is live
Well, here it is. It's not perfect. But it's mine. I am particularly proud of the integration of my social posts from X, Bluesky, and Mastodon. The system auto updates my social posts from Mastodon and Bluesky nightly. X requires me to do a manual update process, which is fine as I don't post there almost at all anymore.
It doesn't yet handle pagination which I still need to do, but I've run out of steam for it tonight and it's completely usable without it.
|
I did manage some more work on the search for the blog last night, mostly fixing bugs and working on the front end. I also realized that while I needed to make pagination based searches, I also needed a way to determine the total number of pages in a search for the pagination, so figuring out how I would handle that took a bit.
Secondly, and perhaps embarrassingly, I finally spent time relearning branches and how to use them with git. As a solo developer, I don't make a lot of use of them, and I am trying to get better, especially when it comes to new features which touch a lot of things.
I plan to put more time into it tonight and hopefully get it to the launch point? We'll see.
|
Search update
I am still working on Glowbug's site search, I did some more programming for it last night. I've got the back end largely built, and the basics of the front end for the search interface, but still have more to do. And tonight is D&D, so possibly tomorrow I'll hammer it out and finish it. We'll see.
To Do:
- Finish display of matching social posts
- Pagination of search
- Anti spam/abuse protections
- Other things I've forgotten I need to do
|
I really need to sleep more, but at least I woke up early enough to get to do some programming this morning.
|
Adding Search
Tonight I started work on writing code to add a search function to this blog. However, not just posts on the blog, also posts I make on social media. So I wrote code for importing posts from Bluesky and Mastodon, the latter mainly for completeness as I don't post there much anymore. It imported my backlog and then I modified the same code to be usable for a nightly cron job.
The search itself is still something I'm wrestling with. Aside from the added sources of content, I am trying to figure out how to best do this.
It's no secret that search is complicated. Which makes this a fun mental challenge.
So I have the most basic parts done, and now it is the gritty details of adding logic for ordering these posts, as well as adding things like spam protection, caching, XSS protection, etc. And then it will be writing the client side code and display functionality.
I'd guess I'm like 30% done.... famous last words. We'll see.
|
Next bluesky posting test: Handling longer text than it can post. Right now I'm going with semi-smart truncation (not cutting mid-word) and just linking to the blog. Granted, it's just to the main page and not the specific post, for now. Rather than make it specific functionality, just trying to make it handle the general process. Lorem ipsum dolor sit amet. The quick brown fox, yadda yadda yadda.
|
Testing to see if my blog posting to bluesky now properly handles links, like trickjarrett.com - as well as handle hashtags in copy: #programming
Update: It does!
|
Radar Charts
Okay, the radar in the previous post was generated out of my test code. Now comes the real test, integrating it into the blog itself... Let's see.
Here's my rating for the movie G20, that we watched last month.
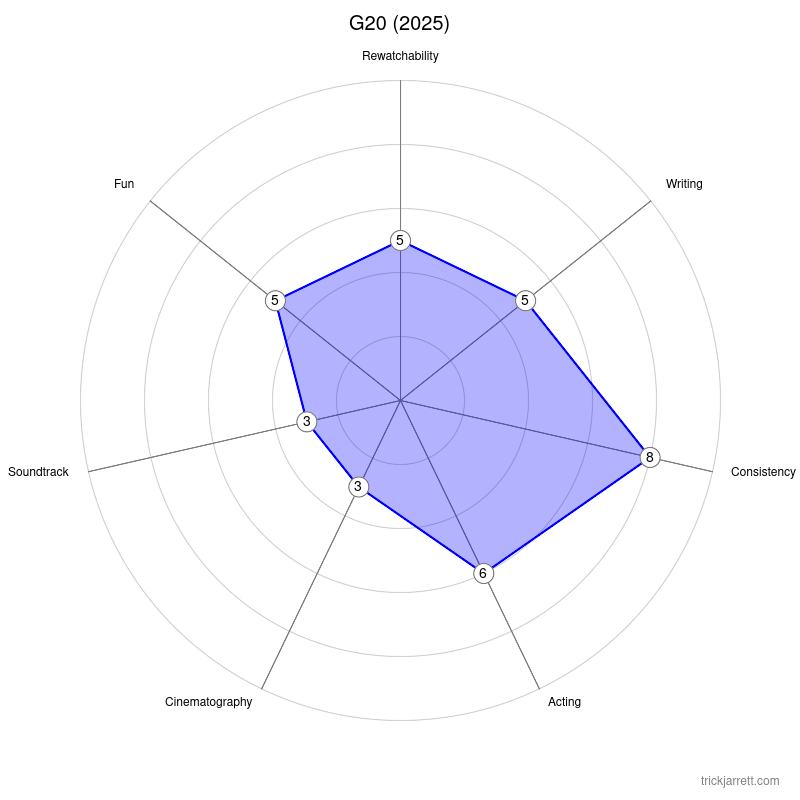
Update: Tada! It works. I did have to go into the database and change some stuff, but cool to get it implemented in the blog. Now I can generate radar graphs in the back end of my blog.
|
It seems my code yesterday broke the automated post function. Oops. I'll fix that tonight.
Edit: Was able to debug it remotely!
|
Small blog updates
Made some small blog updates today:
- I tweaked some small CSS display things which were bothering me.
- I removed the social links at the top for the platforms I don't use (X, Threads.)
- I've attempted to reintegrate my writing tracking into the end of day automated post. It's not quite as robust as it was, but this was meant to be quick and simple.
- Modified our url code to include the github user when it shows the github.com url after a link.
Update: One more idea I am messing with, but I like the idea of displaying my blog posts by day similar to the Github activity grid. I started messing around with it but it's a bit more complicated.
Update 2: Okay, the Github heatmap grid is now done. It's on the sidebar and will fill through the year, but also I have added it to the date archive page under each year header.
|
Glowbugging While Sick
I've been fighting a bug and slept the majority of the past two days. I'm back mostly functional today, but I can tell I'm still less than 100%.
One thing that came out of the past day was I managed to make progress on two things on the blog:
First, the tag specific archives now (partly) work. I haven't linked to them anywhere yet, that is still coming. I also added the ability for me to choose which tags get archives. The archives need a bit more tweaking, and I want to add pagination to the tags which are larger (for example, there are 200+ posts with the programming tag currently.) But we've made solid progress.
I also want to add the ability to do combined tags. For example, the system currently recognizes 'review' and then a medium such as 'tv', 'movie', 'book.' But that is hardcoded, and I will need to find a way to streamline making those into special archives, etc.
Second, I upgraded the admin-side search functionality of posts. It was previously very simple and now it includes logic for handling and/or/not, as well as more. I've found a few bugs still to work out but excited to have gotten this far.
So, it's progress.
|
Glowbug Tag Archives
Last night I began the work of adding tag based archives to the blog. For example, my "social post" tag is meant for me to use whenever I write a quick post here which is also sent out to my Bluesky and Mastodon accounts. For that tag specifically the idea is you could have this page bookmarked and basically get a (somewhat) complete feed of my social posts.
The functionality also lays the groundwork for an eventual "photolog" view, where you'd just see a page which are photo posts I made where the photo is the focus.
The functionality has a lot of benefits, and it's been on the backlog for years. I've never gotten around to it. And, the reality is. It isn't complex to add, there isn't a lot of new logic needed. The work breaks down to:
- Create the template file
- Add a section to the publish code which does the actual publishing and making of files
- Add tag archive links to the archive page
- Add administration tools for selecting which tags get their own archives
There's obviously more to each step, but that is generally the process.
So, step one. The template is very similar to what I use for the date archives. I just made a few small tweaks and introduced a new template tag for placing the tag name on the page. So the top can say "Posts tagged: [Insert tag]".
Check. Easy.
Step two, adding the section to publishing. This should also be fairly easy, it's basically the same code as I use for date archives. Except... something isn't right. I copied the Dates archive section and went through to modify it. And then when I began testing it wasn't working. I tried to bugfix it for about an hour and couldn't find where my error was. I rolled it back and stopped there for the night.
So, we're on the cusp of adding that functionality to the blog. I'll get back to it tonight, likely. But, not there yet.
|
Testing something
One of the features I love with Glowbug is how it can generate smart embeddings for content. Basically, I enter a custom tag of a URL and it generates special code which goes into the entry. Things like video embeds, social posts, etc. The majority of these are ones I have coded myself in the backend. However, there is a subset where I have found it is easier to make use of Iframely.
Iframely is a company which acts as a middle-agent for generating embeds. Currently they allow up to 1000 embed requests a month before charging you. Which is hugely more than I need, so it's a free service for me.
I make use of them for Wikipedia & YouTube embeds right now. Up to this morning, these domain checks were hardcoded. So, to add a domain (Iframely has several hundred websites they connect with) I'd have to modify the PHP file. This morning, I finally through together the code which lets me manage the list of domains which, if matched, are generated as embeds with Iframely.
So, now, I can add BoardGameGeek.com to their domain list and embed this:
No code changes, just adding BoardGameGeek to the database variable in the server.
|
Small Glowbug Tweak
I love the automated post functionality I have on this blog. But I hated seeing the times when my homepage is entirely those posts because I take some time off posting. So now what I do is it puts the most recent automated post on the homepage, and then it skips further automated posts.
Those automated posts are available on that day's archive page.
|
Glowbug Embeds
So one of the powers of my own blog engine is that I've done a lot of automation that I call 'embeds.' This is code that allows inputting a URL or a code string and having it turned into more robust HTML. This is things like YouTube videos ending up on page, as well as when you see my movie poster or book blocks.
But, today I added a few things for functionality.
- Bluesky - I finally sat down with the API and coded the simple tool that takes in a Bsky post and fetches the html for embedding.
- YouTube & Wikipedia - They both make use of a tool called iframly which is meant to be a tool that unifies the fetching of embed code for the video or the link to a Wikipedia page. Youtube had been used peviously but it was a shitty implementation and this one looks so much better.
- lichess - The site I regularly play chess on and now I can simply link to a game's URL and have it embed an iframe which enables visitors to actually play the embedded game.
There are a lot more potential embed codes via using iframely, but I don't know if I'll ever use them. We'll see.
|
Friday Glowbug Programming
I've had a lovely week off of work, but I'll head back to it on Monday. As part of this week I've blogged and read a fair bit, and as part of blogging, I've coded a fair bit. Again, primarily behind the scenes code, which is some of my favorite stuff as it's the most "hone the tool" hobbit software work for something like Glowbug.
I don't publish this CMS, it's just for me. So I get to appreciate and use it. No performance, just utility. Am I going to win any coding awards for it? Never. Does my github commit streak matter? Not in the least. It's all just for me.
Today's work:
- Fix an admin search bug.
- Implement pagination on a few pages and write a generic pagination function to reuse.
- Fix my 'images' admin page, which now needs to support the sporadic audio files I upload.
- Add cleanup functions for getting rid of unused data and files which might be leftover.
- Improve efficiency of an admin page which took 12+ seconds to load to be sub 1 second.
- Fixed an issue with the link suffixes on the website.
|
LIMTI
Last night I was able to finally fix my admin UI search functionality. It had been broken for a while. And the answer for why it was broken was disappointingly stupid. I had typoed the MySQL query, writing 'LIMTI' rather than 'LIMIT."
But its fixed now and my life is measurably better. While writing yesterday's post about adulting, I used it to search my original Anthony Bourdain post and replace some now-missing embedded tweets which shared a nice story about a person's meeting of Bourdain. I ended up going to the Internet Archive and snagging screenshots of the tweets to embed in the post.
|